Kafka组件体系结构是什么
本篇内容主要讲解“Kafka组件体系结构是什么”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Kafka组件体系结构是什么”吧!
创新互联建站主营榆中网站建设的网络公司,主营网站建设方案,成都APP应用开发,榆中h5成都微信小程序搭建,榆中网站营销推广欢迎榆中等地区企业咨询
事件源,最终一致性,微服务,CQRS等等,这些越多越多的概念被现代开发者所熟悉。从细粒度的服务组装到复杂的以业务为中心的应用架构,这其中最重要的一块就是以中间件为基础的业务脱藕。本文我们介绍中间件基础构建块——事务流。其主导者是Apache Kafka,事实上的事务流平台标准,还会介绍Kafka的一个Web界面工具Kafdrop。

概述
事务流平台属于更广泛的面向消息的中间件(MoM)类,与传统的消息队列和主题类似,但是由于日志结构的不变性,它提供了更强大的时间保证和大幅度性能提高。简而言之,由于事务流的写操作只限于顺序追加,所以更加高效。
传统消息队列(MQ)中的消息往往是任意排序的,并且通常彼此独立,而流中的事务(或记录)往往是按时间顺序或因果关系排序的。而且,事务流会保留其记录,而MQ一旦读取了一条消息,就会丢弃它。因此,事务流往往更适合事件驱动的体系结构,包括事件源,最终一致性和CQRS等(当然,也包括FIFO消息队列,但是FIFO队列和成熟的事务流平台之间的差异非常大,而不仅限于订购)。
事务流平台是MoM领域中相对较新的范例。与数百种MQ风格的消息代理相比较,只有少数几种主流可用。与已建立的标准(例如AMQP,MQTT,XMPP和JMS)相比,事务流空间中还没有与之等效的标准。
事务流平台是当前持续研究和实验的活跃领域。但是,事务流平台不仅仅是一个商用产品,或者复杂的学术问题。它可以广泛应用于消息传递和事务场景,可用于例行性替换消息队列的传统使用场景。
架构概述
下图简要概述了Kafka组件体系结构。此处限于篇幅,我们不详细介绍Kafka内部工作原理。

kafka组成
Kafka是一个分布式系统,包含如下几个关键组件:
Broker(代理)节点:负责批量I/O操作和集群内的持续持久化。代理附加日志文件,这些文件中包含由集群托管的主题分区。可以在多个代理之间复制分区,以实现水平可伸缩性和增加的持久性,这些复制的分区被称为副本。有一个代理节点为控制节点(控制者),其他副本受其管理(追随者)。一个代理节点会被选举为集群控制器,负责分区状态的内部管理,还负责仲裁给定分区的领导者跟随者角色。
ZooKeeper节点:在后台Kafka需要一种方法来管理集群中总体控制器状态。如果控制器出于某种原因退出,则有一个协议可以从剩余的代理集中选出另一个控制器。ZooKeeper很大程度上实现了控制器选举,心跳等的实际机制。ZooKeeper还充当各种配置存储库,维护集群元数据,领导者和跟随者状态,配额,用户信息,ACL和其他内部管理项目。由于底层的选举和共识协议,ZooKeeper节点的数量必须为奇数。
生产者:负责将消息发布到Kafka主题的客户端应用程序。由于Kafka具有日志结构的性质,并且能够在多消费者生态系统之间共享主题,因此只有生产者才能修改底层日志文件中的数据。实际I/O由代理节点代表生产者客户端执行。可以将任意数量生产者消息发布到同一Kafka主题,并选择用于保存记录的分区。
消费者:从主题读取消息的客户端应用程序。任意数量的消费者都可以从同一主题中阅读内容;但是,根据消费者的配置和分组,存在一些规则来管理消费者之间的记录分配。
分区,记录、偏移量和主题
分区是记录的完全有序序列,每一个分区对应一个append日志,这是Kafka的基础。每一条记录具有一个ID:64位整数偏移量和毫秒级的时间签。它可能会存在一个键和一个值。两者都是字节数组,并且都是可选的。术语"完全排序"仅表示对于任何给定的生产者,记录将按照应用程序发出的顺序进行写入。如果记录P在Q之前发布,则P将在分区中的Q之前。(假设P和Q共享一个分区。)此外,所有消费者将以相同的顺序读取它们。对于每个可能的消费者,将始终在Q之前读取P。在大多数用例中,这种订购保证至关重要。通常,已发布的记录将与某些现实事务相对应,并且保留这些事务的时间表通常是必不可少的。
记录的偏移量是分区中一条记录的唯一标识分。偏移量是稀疏地址空间中严格单调递增的整数,每个记录偏移量始终高于其上一个记录偏移量,并且相邻偏移量之间可能存在可变的间隙。如果启用了压缩或作为事务的结果,则必然会存在间隙,所以偏移量也有可能不是连续的。
应用程序不应尝试从字面上解释偏移量,也不应该猜测下一个偏移量是多少。但是,可以根据偏移量推断任何记录的相对顺序,按记录的偏移量对记录进行排序。
下图显示了内部分区的结构:

第一个偏移量(也称为low-water mark,低水位标记)是要显示给消费者的第一个消息。由于Kafka的保留期限制,因此不一定是第一个发布的消息。可以根据时间和/或分区大小来修剪记录。当有这种情况发生时,低水位线似乎会后移,早于低水位线的记录将被截断。
主题是分区的逻辑组成。一个主题可以具有一个或多个分区,而一个分区只能有一个主题或者一个主题的部分。主题是Kafka的基础,允许并行和负载平衡。前面我们说过分区显示总顺序。由于主题内的分区是相互独立的,因此称该主题具有部分顺序。简而言之,这意味着某些记录可以互相排序,而相对于某些其他记录则不可排序。总顺序和部分顺序的概念虽然听起来有些学术化,但在构建性能事务流管道中非常重要。它使我们能够在可能的地方并行处理记录,同时在必须的地方保持顺序。稍后,我们将探讨记录顺序,消费者并行性和主题大小的概念。
实例:消息发布
实践是检验真理的唯一标准,我将理论付诸实践,通过实例说明概念。我们将启动一对Docker容器,一个用Kafka容器,另一个为Kafdrop容器。我们使用Docker Compose方式启用容器。
在选定目录中创建一个docker-compose.yaml文件,内容如下:
为了方便起见,我们用obsidiandynamics/kafka镜像,它会将Kafka和ZooKeeper巧妙地打包在一个镜像中。然后通过docker-compose up启动容器。启动成功后,可以通过浏览器中访问localhost:9000,就能看到Kafdrop登陆界面。

实例中是一个单代理集群,还没有任何主题。我们可以使用Kafka的命令行工具创建一个主题并发布一些消息。我们可以使用docker exec工具对kafka容器进行操作方便地调用内置的CLI工具:
docker exec -it kafka-kafdrop_kafka_1 bash
上面的命令将让我么进入容器的shell命令行界面。工具位于/opt/kafka/bin目录中,cd进入该目录:
创建一个名为streams-intro的主题,其中包含3个分区:
切换回Kafdrop界面,现在我们就能在列表中看到新主创建的主题。

接着,我们可以使用kafka-console-producer工具发布消息:
注意:kafka-topics使用--bootstrap-server参数来配置Kafka代理列表,而kafka-console-producer则使用--broker-list。
记录由换行符分隔。键和值部分由冒号分隔,如key.separator属性所指示。本例下,我们可以输入下内容:
完成后,按CTRL + D键完成消息发布。然后切换回Kafdrop,然后单击streams-intro主题。将看到该主题的概述以及基础分区的详细分类:

我们创建了一个包含三个分区的主题。然后,我们使用两个唯一的键foo和bar发布了五条记录。Kafka使用键将记录映射到分区,这样具有相同键的所有记录将始终出现在同一分区上。很方便,也很重要,它可以使发布者指定准确的记录顺序。稍后,我们将更详细地讨论键哈希和分区分配。
查看分区表,分区#0的第一个和最后一个偏移分别为0和2。分区#2的值为零和3个,而分区#1的显示为空白。在Kafdrop网络用户界面中单击#0,会将会转到主题查看器:
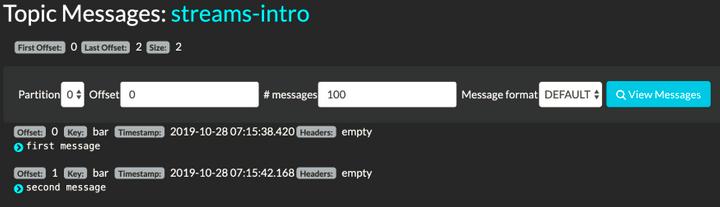
可以看到在bar键下发布的两条记录。注意,它们与foo记录完全无关。
消费者和消费组
上面我们实例讲了,听过生产者发布消息,将记录发送到流中。这些记录被组织成井井有条的分区。Kafka的发布-订阅拓扑遵循灵活的多到多模型,所以,可以有任意数量的生产者和消费者同时与流进行交互。根据实际的解决方案,流拓扑也可以一对多,多对一。下面我们讲,如何消费这些记录。
消费者是通过客户端库连接到Kafka集群的进程或线程。消费者通常(但不一定)是一个整体消费组的成员。该组由group.id属性指定。消费组实际上是Kafka中的负载平衡机制,负责在组内的各个消费者实例之间大致平均地进行分区分配。当组中的第一个消费者订阅该主题时,它将收到该主题中的所有分区。当第二个消费者随后加入时,它将获得大约一半的分区,从而减轻了第一个使用者的负担。当消费者离开时(通过断开连接或超时),该过程将反向进行,其余的使用者将可用更多数量的分区。
因此,消费者消费某个主题中的记录,从Kafka及其所属的其他消费者分配的分区中提取了份额。就负载平衡而言,这应该非常简单。但是,这里有一个关键点,使用记录的行为并不能将其删除。起初这似乎是矛盾的,特别是如果将消耗行为与消耗联系起来。(如果有的话,应该将消费者称为"阅读者"。)一个简单的事实是,消费者对主题及其分区绝对没有任何影响。主题是仅追加,只能由生产者或Kafka本身(作为压缩或清除的一部分)进行追加记录。消费者的只读操作是"便宜的",因此,可以让许多人在不增加集群负担的情况下tail日志。这是事务流和传统消息队列之间的又一区别,这是至关重要的。
消费者在内部维护一个偏移量,该偏移量指向分区中的下一个记录,从而在每次连续读取时都增加偏移量。消费者首次订阅主题时,可以选择从主题的头端或尾端开始。通过将auto.offset.reset属性设置为latest, earliest 或者none,可以控制这个行为。在后一种情况下,如果消费者组不存在先前的偏移量,则将触发异常。
消费者在本地保留其偏移状态向量。由于不同消费组中的消费者不会互相干扰,因此可能有许多人同时阅读同一主题。消费者按照自己的偏移读取消息;缓慢的或积压的消费者对其同组其他人也不会有影响。
为了说明这个概念,我们考虑一个包含两个分区的主题为场景。两个消费者组-A和B-订阅了该主题。每个组具有三个实例,使用者被命名为A1,A2,A3,B1,B2和B3。下图说明了两组如何共享主题,以及消费者如何彼此独立地浏览记录。

仔细看上图,会发现缺少某些东西。消费者A3和B1不在上图中。这是因为Kafka保证分区只能分配给其消费组中的一个消费者。由于每个组中有三个消费者,但是只有两个分区,因此一个消费者将保持空闲状态,等待其所在组中的另一个消费者离开。以这种方式,消费组不仅是负载平衡机制,而且还是用于建立高性能管道而又不牺牲安全性的类似栅栏的排他性控制,特别是在要求只能由一个线程处理记录的情况下或在任何给定时间进行处理。
消费组也用于确保可用性。通过定期从主题中提取记录,消费者可以向集群隐式反馈集群为"健康"状态,从而将租约扩展到其分区分配上。但是,如果消费者未能在允许的期限内再次阅读,则将其视为有缺陷,并且将重新分配其分区,分配给该组中其余的"健康"消费者。该截止日期由max.poll.interval.ms在消费者客户端属性控制,默认情况下设置为五分钟。
用交通系统来做个类比,主题就像是高速公路,分区就是车道。记录就是等同于汽车,其乘客对应于记录值。只要保持行车路线,几辆车就可以安全地在同一条高速公路上行驶。共享相同线路的汽车按顺序行驶,形成队列。现在,假设每条车道通向一个匝道,将其流量转移到某个位置。如果一个匝道堆积了,其他匝道可能仍能顺畅流动。
Kafka正是利用这种机制确保端到端的吞吐量,轻松地实现每秒达到数百万条记录的QPS。创建主题时,可以选择分区计数,通道数。分区在一个消费组中的各个消费者之间大致均匀地划分,并确保不会将分区同时分配给两个(或多个)消费者。
注意:创建后,可以通过增加分区数来调整主题的大小。但是,无法在不重新创建主题的情况下减少分区数。
记录对应于事件、消息、命令或任何其他可流式传输的内容。记录的精确划分方式由生产者决定。生产者可以在发布记录时显式分配分区索引,尽管这种方法很少使用。正如我们在前面的示例中所做的那样,一种更常见的方法是为记录分配键。键对Kafka完全不透明,换句话说,Kafka不会去解释key的内容,而是将其视为字节数组。使用一致的哈希技术对这些字节进行哈希处理以得出分区索引。
共享相同散列的记录可以保证占据相同的分区。假设一个主题具有多个分区,则具有不同键的记录可能最终会位于不同的分区中。但是,由于哈希键冲突,具有不同哈希值的记录也可能最终会在同一分区中。
生产者无需关心记录将映射到哪个特定分区,只要相关记录最终在同一分区中并且保留其顺序。同样,消费者对也无需关心分配到那个分区,只要它们以与发布相同的顺序接收记录,并且其分区分配不会与组中的其他消费者重复。
案例:交易平台
假设我们正在寻找上市股票的特定价格模式,并在确定特定模式后发出交易信号。有大量库存,可以理解的是,希望将它们并行处理。但是,任何给定的股票代码的时间序列必须在单个使用者上顺序处理。
Kafka使这个用例以及其他类似用例几乎不容易实现。我们将创建两个主题:价格,用来存储原始价格数据。订单主题,用来保存任何由产生的订单。我们可以多划分一些分区,可以让我们充分的并行操作。
我们可以在价格主题上发布每个价格的记录,并用股票代码作为键。Kafka的自动分区分配将确保每个股票代号由其组中的一个消费者处理。消费者实例可以自由扩展和扩展以匹配处理负载。消费者组应该有意义地命名,理想地反映消费应用程序的目的。比如trading-strategy.abc,它是一种名为" ABC"的虚拟交易策略。
消费者确定了价格模式后,就可以在订单主题上发布另一条消息,订单请求。我们将召集另一个消费组,订单执行,负责读取订单并将其转发给经纪人。
在这个简单的示例中,我们创建了一个完全由事件驱动且高度可扩展的端到端交易管道,假设没有其他瓶颈。我们可以在各个阶段动态添加更多的处理节点,以应对需要增加的负载的情况。
假设您需要在通用数据源的驱动下同时运行的几种交易策略。此外,交易策略将由不同的团队制定;目的是尽可能地使这些实现脱钩,从而使团队能够自主运作,甚至可以使用不同的编程语言和工具链以各自的节奏进行开发和部署。

Kafka灵活的多到多pub-sub体系结构将状态消耗与广播语义相结合。通过使用不同的消费群体,Kafka允许不同的应用程序共享输入主题,并按自己的进度处理事件。第二种交易策略将需要一个专门的消费群体:trading-strategy.xyz,将其特定的业务逻辑应用于通用定价流,并将生成的订单发布到相同的订单主题。通过这种方式,Kafka能够从易于重用和组合的离散元素构建模块化事件处理管道。
到此,相信大家对“Kafka组件体系结构是什么”有了更深的了解,不妨来实际操作一番吧!这里是创新互联网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
分享题目:Kafka组件体系结构是什么
分享路径:http://ybzwz.com/article/ggjcjh.html

